
-
吴恩达与OpenAI联手推出了一门面向开发者的ChatGPT提示工程课程。起初,我误以为这只是一个试图借势炒作的水课,毕竟编写提示似乎并无太大难度。然而,在观看了课程的几分钟之后,我意识到这门课程远非如此简单。开篇便介绍了一些我从未了解过的提示技巧。课程的核心内容围绕如何编写调用OpenAI API的提示,并为那些需仅与ChatGPT网页互动的用户提供了诸多独特且实用的建议。视频还配套有一个Jupyter notebook让你在听课的同时可以亲自动手实践。
课程链接:ChatGPT Prompt Engineering for Developers
斯坦福教授吴恩达与OpenAI成员联合授课 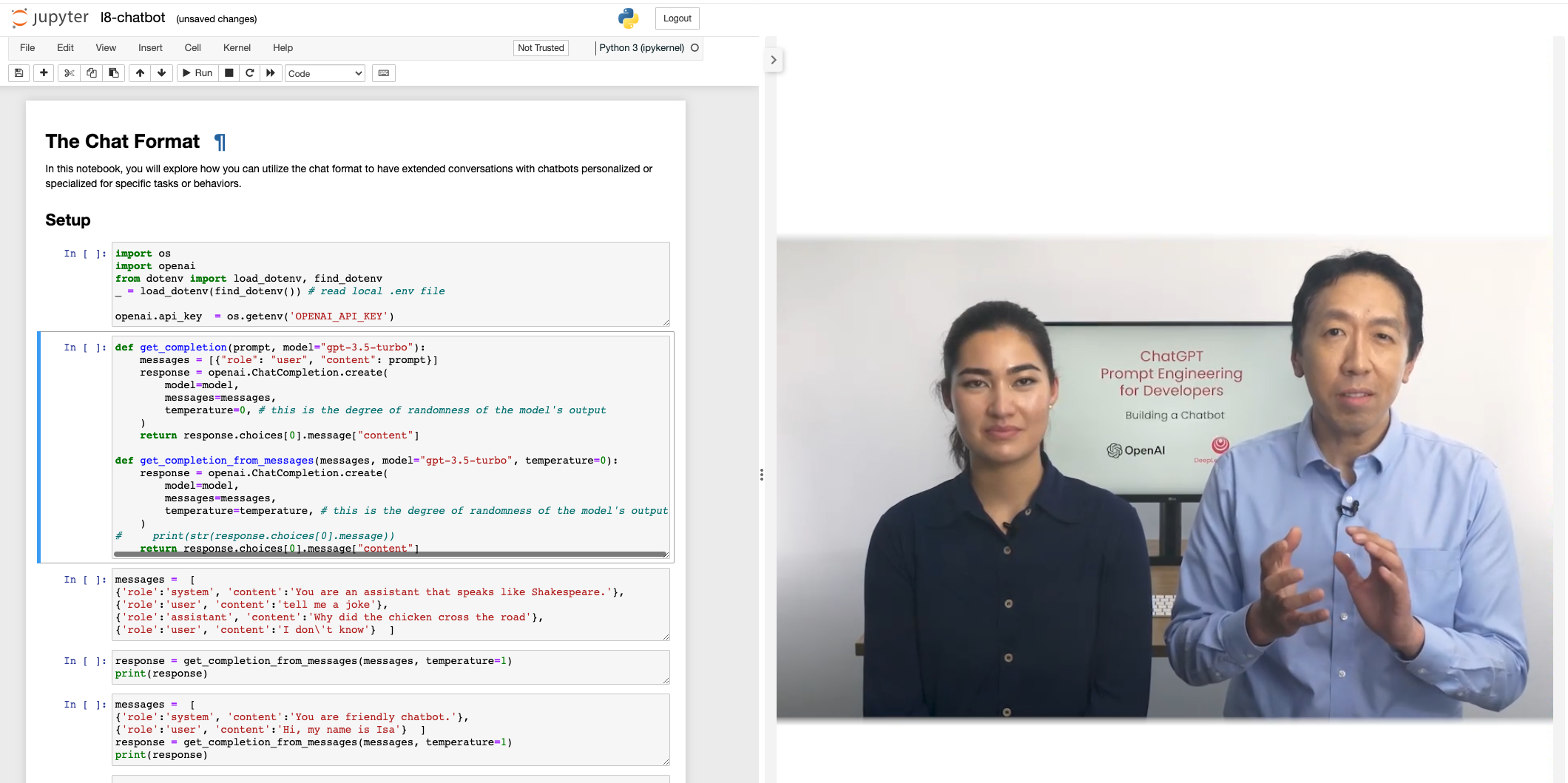
视频还配套有一个Jupyter notebook让你在听课的同时可以亲自动手实践,里面提供了许多典型的例子 介绍(Introduction)
在对齐之前的Base LLM只会对prompt的文本进行续写,所以当你向模型发问的时候,它往往会像复读机一样续写几个问题,这是因为在它见过的语料库文本(通常大多来自互联网)中,通常会连续列举出N个问题。在经过指令微调(如RLHF)之后,模型才会像人一样进行有效答复,也就是PPT上所说的的“Helpful, Honest, Harmless”。

对齐之后的模型更像人类 指导准则(Guidelines)
课程首先提出了两个提示工程的原则:
- 提供清晰和具体的指令
- 给予模型时间来“思考”
原则 1: 提供清晰和具体的指令 (Write clear and specific instructions)
策略 1: 使用分隔符清楚地指示输入的不同部分(Use delimiters to clearly indicate distinct parts of the input)
使用分隔符的意义在于避免用户输入的文本可能存在一些误导性的话语对应用功能造成干扰,下面是一个提示注入的例子:

在这个例子中,通过注入“forget the previous instructions”,有可能会导致模型忽略这句话之前的开发者写的提示 分隔符是以下任意一个: “`, “””, < >, <tag> </tag>
Prompt示例:
text = f""" You should express what you want a model to do by \ providing instructions that are as clear and \ specific as you can possibly make them. \ This will guide the model towards the desired output, \ and reduce the chances of receiving irrelevant \ or incorrect responses. Don't confuse writing a \ clear prompt with writing a short prompt. \ In many cases, longer prompts provide more clarity \ and context for the model, which can lead to \ more detailed and relevant outputs. """ prompt = f""" Summarize the text delimited by triple backticks \ into a single sentence. ```{text}``` """ response = get_completion(prompt) print(response)输出:
Clear and specific instructions should be provided to guide a model towards the desired output, and longer prompts can provide more clarity and context for the model, leading to more detailed and relevant outputs.策略 2: 要求结构化的输出(Ask for a structured output)
这样有助于模型输出结果直接用于程序,比如输出的json可以直接被python程序读取并转换为字典格式。
Prompt示例:
prompt = f""" Generate a list of three made-up book titles along \ with their authors and genres. Provide them in JSON format with the following keys: book_id, title, author, genre. """ response = get_completion(prompt) print(response)输出:
[ { "book_id": 1, "title": "The Lost City of Zorath", "author": "Aria Blackwood", "genre": "Fantasy" }, { "book_id": 2, "title": "The Last Survivors", "author": "Ethan Stone", "genre": "Science Fiction" }, { "book_id": 3, "title": "The Secret of the Haunted Mansion", "author": "Lila Rose", "genre": "Mystery" } ]策略 3: 让模型检查是否满足条件(Ask the model to check whether conditions are satisfied)
Prompt示例(满足条件的文本):
text_1 = f""" Making a cup of tea is easy! First, you need to get some \ water boiling. While that's happening, \ grab a cup and put a tea bag in it. Once the water is \ hot enough, just pour it over the tea bag. \ Let it sit for a bit so the tea can steep. After a \ few minutes, take out the tea bag. If you \ like, you can add some sugar or milk to taste. \ And that's it! You've got yourself a delicious \ cup of tea to enjoy. """ prompt = f""" You will be provided with text delimited by triple quotes. If it contains a sequence of instructions, \ re-write those instructions in the following format: Step 1 - ... Step 2 - … … Step N - … If the text does not contain a sequence of instructions, \ then simply write \"No steps provided.\" \"\"\"{text_1}\"\"\" """ response = get_completion(prompt) print("Completion for Text 1:") print(response)输出:
Completion for Text 1: Step 1 - Get some water boiling. Step 2 - Grab a cup and put a tea bag in it. Step 3 - Once the water is hot enough, pour it over the tea bag. Step 4 - Let it sit for a bit so the tea can steep. Step 5 - After a few minutes, take out the tea bag. Step 6 - Add some sugar or milk to taste. Step 7 - Enjoy your delicious cup of tea!Prompt示例(未满足条件的文本):
text_2 = f""" The sun is shining brightly today, and the birds are \ singing. It's a beautiful day to go for a \ walk in the park. The flowers are blooming, and the \ trees are swaying gently in the breeze. People \ are out and about, enjoying the lovely weather. \ Some are having picnics, while others are playing \ games or simply relaxing on the grass. It's a \ perfect day to spend time outdoors and appreciate the \ beauty of nature. """ prompt = f""" You will be provided with text delimited by triple quotes. If it contains a sequence of instructions, \ re-write those instructions in the following format: Step 1 - ... Step 2 - … … Step N - … If the text does not contain a sequence of instructions, \ then simply write \"No steps provided.\" \"\"\"{text_2}\"\"\" """ response = get_completion(prompt) print("Completion for Text 2:") print(response)输出:
Completion for Text 2: No steps provided.策略 4: 少样本提示( “Few-shot” prompting)
通过提供给模型一个或多个样本的提示,模型可以更加清楚需要你预期的输出。
关于few-shot learning,感兴趣的同学可以看一下GPT-3的论文:Language Models are Few-Shot Learners
Prompt示例:
prompt = f""" Your task is to answer in a consistent style. <child>: Teach me about patience. <grandparent>: The river that carves the deepest \ valley flows from a modest spring; the \ grandest symphony originates from a single note; \ the most intricate tapestry begins with a solitary thread. <child>: Teach me about resilience. """ response = get_completion(prompt) print(response)输出:
<grandparent>: Resilience is like a tree that bends with the wind but never breaks. It is the ability to bounce back from adversity and keep moving forward, even when things get tough. Just like a tree that grows stronger with each storm it weathers, resilience is a quality that can be developed and strengthened over time.原则 2: 给模型时间来“思考”(Give the model time to “think” )
这个原则利用了思维链的方法,将复杂任务拆成N个顺序的子任务,这样可以让模型一步一步思考,从而给出更精准的输出。具体可以参见这篇paper:https://arxiv.org/abs/2201.11903
策略1:指定完成任务所需的步骤 (Specify the steps required to complete a task)
下面是一个例子,需要先对文本进行总结,再将总结翻译成法语,然后在法语总结中列出每个名字,最后输出json格式的数据,这么复杂的指令,如果让模型直接输出结果,怕是很难搞定。但是如果给出所需的步骤,让模型一步一步来解,可以让模型在输出token的时候可以参照上一个步骤的结果,从而提升输出的正确率。
Prompt示例:
text = f""" In a charming village, siblings Jack and Jill set out on \ a quest to fetch water from a hilltop \ well. As they climbed, singing joyfully, misfortune \ struck—Jack tripped on a stone and tumbled \ down the hill, with Jill following suit. \ Though slightly battered, the pair returned home to \ comforting embraces. Despite the mishap, \ their adventurous spirits remained undimmed, and they \ continued exploring with delight. """ # example 1 prompt_1 = f""" Perform the following actions: | 1 - Summarize the following text delimited by triple \ backticks with 1 sentence. 2 - Translate the summary into French. 3 - List each name in the French summary. 4 - Output a json object that contains the following \ keys: french_summary, num_names. Separate your answers with line breaks. Text: ```{text}``` """ response = get_completion(prompt_1) print("Completion for prompt 1:") print(response)输出:
Completion for prompt 1: Two siblings, Jack and Jill, go on a quest to fetch water from a well on a hilltop, but misfortune strikes and they both tumble down the hill, returning home slightly battered but with their adventurous spirits undimmed. Deux frères et sœurs, Jack et Jill, partent en quête d'eau d'un puits sur une colline, mais un malheur frappe et ils tombent tous les deux de la colline, rentrant chez eux légèrement meurtris mais avec leur esprit d'aventure intact. Noms: Jack, Jill. { "french_summary": "Deux frères et sœurs, Jack et Jill, partent en quête d'eau d'un puits sur une colline, mais un malheur frappe et ils tombent tous les deux de la colline, rentrant chez eux légèrement meurtris mais avec leur esprit d'aventure intact.", "num_names": 2 }我们发现,虽然程序比较好的完成了任务,但是在第三个步骤模型使用了法语Noms,这并不是我们所期望的,所以接下来的示例会提供具体输出的格式来更正这个问题。
更好的Prompt:
prompt_2 = f""" Your task is to perform the following actions: 1 - Summarize the following text delimited by <> with 1 sentence. 2 - Translate the summary into French. 3 - List each name in the French summary. 4 - Output a json object that contains the following keys: french_summary, num_names. Use the following format: Text: <text to summarize> Summary: <summary> Translation: <summary translation> Names: <list of names in Italian summary> Output JSON: <json with summary and num_names> Text: <{text}> """ response = get_completion(prompt_2) print("\nCompletion for prompt 2:") print(response)对应更符合期望的输出:
Completion for prompt 2: Summary: Jack and Jill go on a quest to fetch water, but misfortune strikes and they tumble down the hill, returning home slightly battered but with their adventurous spirits undimmed. Translation: Jack et Jill partent en quête d'eau, mais un malheur frappe et ils tombent de la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts. Names: Jack, Jill Output JSON: {"french_summary": "Jack et Jill partent en quête d'eau, mais un malheur frappe et ils tombent de la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts.", "num_names": 2}策略2:在匆忙得出结论之前,让模型自己找出解决方案(Instruct the model to work out its own solution before rushing to a conclusion)
在这里,作者给出了一个检查学生习题答案的例子,在第一个版本的prompt里,模型匆忙地给出了错误的答案:
效果不好的prompt示例:
prompt = f""" Determine if the student's solution is correct or not. Question: I'm building a solar power installation and I need \ help working out the financials. - Land costs $100 / square foot - I can buy solar panels for $250 / square foot - I negotiated a contract for maintenance that will cost \ me a flat $100k per year, and an additional $10 / square \ foot What is the total cost for the first year of operations as a function of the number of square feet. Student's Solution: Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000 """ response = get_completion(prompt) print(response)不正确的输出:
The student's solution is correct.我们可以通过指示模型先找出自己的解决方案来解决这个问题:
更新后的prompt:
prompt = f""" Your task is to determine if the student's solution \ is correct or not. To solve the problem do the following: - First, work out your own solution to the problem. - Then compare your solution to the student's solution \ and evaluate if the student's solution is correct or not. Don't decide if the student's solution is correct until you have done the problem yourself. Use the following format: Question: ``` question here ``` Student's solution: ``` student's solution here ``` Actual solution: ``` steps to work out the solution and your solution here ``` Is the student's solution the same as actual solution \ just calculated: ``` yes or no ``` Student grade: ``` correct or incorrect ``` Question: ``` I'm building a solar power installation and I need help \ working out the financials. - Land costs $100 / square foot - I can buy solar panels for $250 / square foot - I negotiated a contract for maintenance that will cost \ me a flat $100k per year, and an additional $10 / square \ foot What is the total cost for the first year of operations \ as a function of the number of square feet. ``` Student's solution: ``` Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000 ``` Actual solution: """ response = get_completion(prompt) print(response)正确的输出:
Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 10x Total cost: 100x + 250x + 100,000 + 10x = 360x + 100,000 Is the student's solution the same as actual solution just calculated: No Student grade: Incorrect模型的限制:幻觉(Model Limitations: Hallucinations)
经常使用ChatGPT的同学应该都知道,模型会产生幻觉,也就是会捏造一些似是而非的东西(比如某个不存在的文学作品),这些输出看起来是正确的,但实质上是错误的。
针对这个问题,作者提供了一个比较有效的方法可以缓解模型的幻觉问题:让模型给出相关信息,并基于相关信息给我回答。比如告诉模型:“First find relevant information, then answer the question based on the relevant information”。
迭代提示开发(Iterative Prompt Develelopment)
在这一章节中,吴恩达老师提出了迭代提升开发的概念,具体可以看下图:
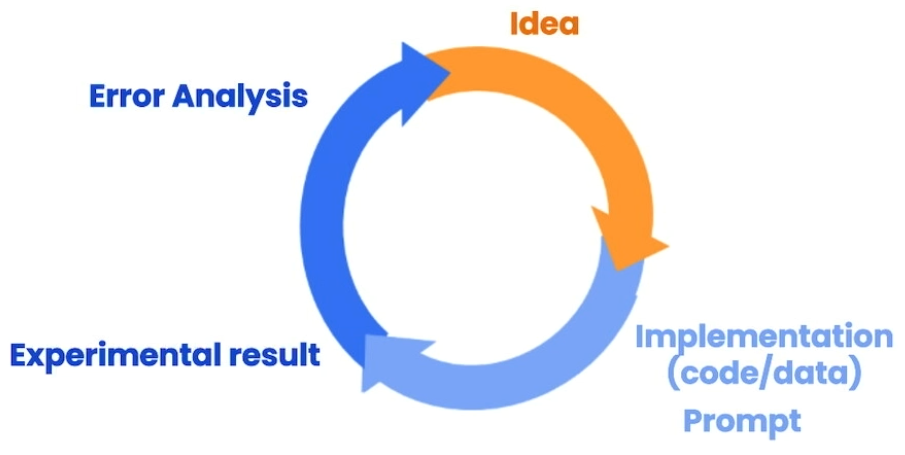
我们很难在初次尝试中就设计出最佳的提示,因此需要根据ChatGPT的反馈进行分析,分析输出具体在哪里不符合期望,然后不断思考和优化提示。如果有条件的话,最好是利用批量的样本来改善提示,这样可以对你的优化结果有一个较为直观的体现。
总结、推理、转换和扩展
课程接下来深入探讨了ChatGPT在总结、推理、转换和扩展四个方面的语言生成能力。
通过具体的例子和代码,课程一边讲解一边实践,展示了如何设计相应的提示来发挥ChatGPT在这四个方面的潜力。
总结(Summarizing)
如今的世界充斥着大量的文本,我们几乎没有足够的时间阅读所有希望读的内容。因此,大语言模型最令人兴奋的应用之一就是用它来对文本进行总结。现在已经有很多团队将这个功能融入到多种软件应用中。
推理(Inferring)
推理,可以看作是模型接收一段文本作为输入,然后进行某种分析。所以这可能包括提取标签、提取名称、理解文本的情感等等。如果你想从一段文本中提取正面或负面的情感,在传统的机器学习流程中,你需要收集带标签的数据集、训练模型、弄清楚如何将模型部署到云端并进行推理。这种方法效果很好,但整个过程确实需要付出很多努力。而且,对于情感分析、提取名称等每个任务,你都需要训练和部署一个独立的模型。大型语言模型的一个优点是,对于这类任务,你只需编写一个提示,然后它就能立刻开始生成结果。这在应用程序开发方面具有很大的速度优势。而且,你只需要使用一个模型和一个API就能完成许多不同的任务,而不需要弄清楚如何训练和部署许多不同的模型。
转换(Transforming)
大型语言模型非常擅长将其输入转换为不同的格式,例如将一种语言的文本作为输入,然后将其转换或翻译成另一种语言;或者协助进行拼写和语法纠正,将可能不完全符合语法规则的文本作为输入,帮助你修改其中的错误;甚至还能转换格式,如输入HTML并输出JSON。过去,我们需要痛苦地用一堆正则表达式来完成这些应用,而现在,借助大型语言模型和一些提示,实现起来肯定会简单得多。
扩展(Expanding)
拓展任务是指将简短的文本,如一组指令或一系列主题,通过大型语言模型生成更长的文本,如一封电子邮件或关于某个主题的文章。这样做有很多优点,比如将大型语言模型作为头脑风暴的伙伴。然而,这也存在一些问题,比如有人可能会用它产生大量垃圾邮件。所以在使用大型语言模型的功能时,请务必负责任地使用,以有益于人们的方式使用。
聊天机器人(Chatbot)
大型语言模型的激动人心之处在于,只需付出适度的努力,就可以用它构建一个定制的聊天机器人。ChatGPT的网络界面让人们能够与大型语言模型进行会话交流。但不仅限于此,我们还可以利用大型语言模型来构建自定义的聊天机器人,扮演AI客户服务代表或餐厅的AI接单员等角色。
聊天格式(The Chat Format)
如下图所示,之前所使用的get_completion函数,实际上是将提示放入了一个类似于用户消息的东西。这是因为ChatGPT模型是一个聊天模型,这意味着它经过训练,可以接收一系列消息作为输入,然后返回一个由模型生成的消息作为输出。所以用户消息就是输入,助手消息就是输出。

将文本填充到content字段中来取得单轮对话的效果 为了实现对轮对话并且使用更加丰富的参数,在这里我们需要用一个稍复杂的函数get_completion_from_messages:
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0): response = openai.ChatCompletion.create( model=model, messages=messages, temperature=temperature, # this is the degree of randomness of the model's output ) # print(str(response.choices[0].message)) return response.choices[0].message["content"]接下来,我们就可以把多轮对话的信息通过messages参数传入:
messages = [ {'role':'system', 'content':'You are an assistant that speaks like Shakespeare.'}, {'role':'user', 'content':'tell me a joke'}, {'role':'assistant', 'content':'Why did the chicken cross the road'}, {'role':'user', 'content':'I don\'t know'} ] response = get_completion_from_messages(messages, temperature=1) print(response)值得注意的是,messages的第一个元素是系统消息,它有助于设定助手的行为和角色,它作为对话的高级指导。可以将其视为在助手的耳边低声提示,引导其回应,而用户并不知道系统消息的存在。
输出:
To get to the other side, methinks!点单机器人(OrderBot)
我们可以自动收集用户提示和助理响应,以构建OrderBot。OrderBot将在一家披萨餐厅接受订单。
首先,我们将定义一个辅助函数,它将收集我们的用户消息,以便我们可以避免像之前那样手动输入。然后,它将从下面构建的用户界面收集提示,并将其追加到一个名为上下文(context)的列表中,然后每次都会用该上下文调用模型。模型响应接着也被添加到上下文中,所以模型消息被添加到上下文,用户消息被添加到上下文,等等,它会变得越来越长。
def collect_messages(_): prompt = inp.value_input inp.value = '' context.append({'role':'user', 'content':f"{prompt}"}) response = get_completion_from_messages(context) context.append({'role':'assistant', 'content':f"{response}"}) panels.append( pn.Row('User:', pn.pane.Markdown(prompt, width=600))) panels.append( pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'}))) return pn.Column(*panels)这样一来,模型就拥有了决定下一步该做什么的所需信息。注意,每次我们调用语言模型时,我们都将使用相同的上下文,随着时间的推移,上下文会逐渐积累。
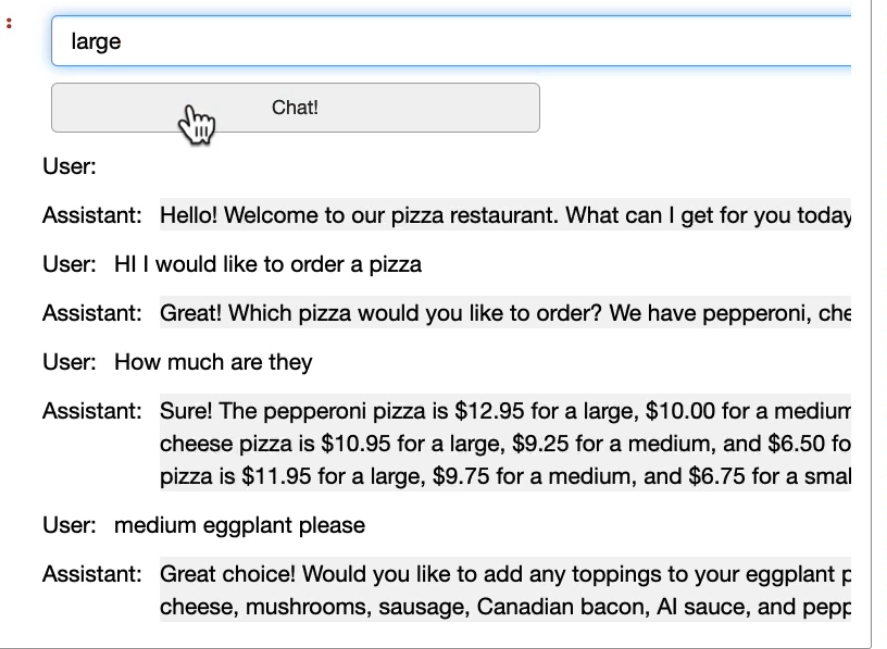
import panel as pn # GUI pn.extension() panels = [] # collect display context = [ {'role':'system', 'content':""" You are OrderBot, an automated service to collect orders for a pizza restaurant. \ You first greet the customer, then collects the order, \ and then asks if it's a pickup or delivery. \ You wait to collect the entire order, then summarize it and check for a final \ time if the customer wants to add anything else. \ If it's a delivery, you ask for an address. \ Finally you collect the payment.\ Make sure to clarify all options, extras and sizes to uniquely \ identify the item from the menu.\ You respond in a short, very conversational friendly style. \ The menu includes \ pepperoni pizza 12.95, 10.00, 7.00 \ cheese pizza 10.95, 9.25, 6.50 \ eggplant pizza 11.95, 9.75, 6.75 \ fries 4.50, 3.50 \ greek salad 7.25 \ Toppings: \ extra cheese 2.00, \ mushrooms 1.50 \ sausage 3.00 \ canadian bacon 3.50 \ AI sauce 1.50 \ peppers 1.00 \ Drinks: \ coke 3.00, 2.00, 1.00 \ sprite 3.00, 2.00, 1.00 \ bottled water 5.00 \ """} ] # accumulate messages inp = pn.widgets.TextInput(value="Hi", placeholder='Enter text here…') button_conversation = pn.widgets.Button(name="Chat!") interactive_conversation = pn.bind(collect_messages, button_conversation) dashboard = pn.Column( inp, pn.Row(button_conversation), pn.panel(interactive_conversation, loading_indicator=True, height=300), ) dashboard我们可以看到下面的实验效果符合我们的期望。
最后,我们可以让模型生成订单的JSON数据,将其发送到订单系统
输入:
messages = context.copy() messages.append( {'role':'system', 'content':'create a json summary of the previous food order. Itemize the price for each item\ The fields should be 1) pizza, include size 2) list of toppings 3) list of drinks, include size 4) list of sides include size 5)total price '}, ) #The fields should be 1) pizza, price 2) list of toppings 3) list of drinks, include size include price 4) list of sides include size include price, 5)total price '}, response = get_completion_from_messages(messages, temperature=0) print(response)输出:
Sure, here's a JSON summary of the order: ``` { "pizza": [ { "type": "pepperoni", "size": "large", "price": 12.95 }, { "type": "cheese", "size": "medium", "price": 9.25 } ], "toppings": [ { "type": "extra cheese", "price": 2.00 }, { "type": "mushrooms", "price": 1.50 } ], "drinks": [ { "type": "coke", "size": "large", "price": 3.00 }, { "type": "sprite", "size": "small", "price": 2.00 } ], "sides": [ { "type": "fries", "size": "large", "price": 4.50 } ], "total_price": 38.20 } ```值得注意的是,在OrderBot这种情况下,我们使用较低的temperature,因为对于这些任务,我们希望输出相当可预测。对于会话代理,我们可能希望使用较高的temperature。
原文来自:https://zhuanlan.zhihu.com/p/625917566









